Taller introductorio de python & audio
En este taller de audio vamos a recorrer algunas funciones para el tratamiento y análisis de audio. El video explicativo puede encontrarse en youtube y el repositorio aquí.
!pip install googletrans
!pip install deepspeech
!pip install youtube-dl
!pip install librosa
!pip install ffmpeg-python
Python & Audio
- Python. Porqué es el mejor lenguaje.
- Python, el intérprete. Notebooks, jupyter, Collaboratory.
- Numpy y scipy:
- Presentando librerías
- El sonido.
- Señal de audio. El audio digital y el sonido en el mundo físico.
- Gráficos librería Matplotlib:
- Ploteo básico, ploteo de señales
- Operaciones:
- Señales más allá del seno. Suma de señales
- Dominio de frecuencias
- Fourier
- Filtros
- Otras aplicaciones
print('Hola a todos')
Hola a todos
def esc(code):
return f'\033[{code}m'
print(esc('36;1;4') + 'Bievenidos al taller introductorio de python aplicado al audio')
[36;1;4mBievenidos al taller introductorio de python aplicado al audio
Por qué python es el mejor lenguaje?
- Batteries included Rich collection of already existing bricks of classic numerical methods, plotting or data processing tools. We don’t want to re-program the plotting of a curve, a Fourier transform or a fitting algorithm. Don’t reinvent the wheel!
- Easy to learn Most scientists are not payed as programmers, neither have they been trained so. They need to be able to draw a curve, smooth a signal, do a Fourier transform in a few minutes.
- Easy communication To keep code alive within a lab or a company it should be as readable as a book by collaborators, students, or maybe customers. Python syntax is simple, avoiding strange symbols or lengthy routine specifications that would divert the reader from mathematical or scientific understanding of the code.
- Efficient code Python numerical modules are computationally efficient. But needless to say that a very fast code becomes useless if too much time is spent writing it. Python aims for quick development times and quick execution times.
- Universal Python is a language used for many different problems. Learning Python avoids learning a new software for each new problem.
from googletrans import Translator
texto_en_ingles = """Batteries included Rich collection of already existing bricks of classic numerical methods, plotting or data processing tools. We don’t want to re-program the plotting of a curve, a Fourier transform or a fitting algorithm. Don’t reinvent the wheel!
Easy to learn Most scientists are not payed as programmers, neither have they been trained so. They need to be able to draw a curve, smooth a signal, do a Fourier transform in a few minutes.
Easy communication To keep code alive within a lab or a company it should be as readable as a book by collaborators, students, or maybe customers. Python syntax is simple, avoiding strange symbols or lengthy routine specifications that would divert the reader from mathematical or scientific understanding of the code.
Efficient code Python numerical modules are computationally efficient. But needless to say that a very fast code becomes useless if too much time is spent writing it. Python aims for quick development times and quick execution times.
Universal Python is a language used for many different problems. Learning Python avoids learning a new software for each new problem."""
translate = Translator()
texto_español = translate.translate(texto_en_ingles, dest = 'es')
texto_español.text
'Pilas incluidas Amplia colección de ladrillos ya existentes de métodos numéricos clásicos, herramientas de trazado o procesamiento de datos. No queremos reprogramar el trazado de una curva, una transformada de Fourier o un algoritmo de ajuste. ¡No reinventes la rueda!\nFácil de aprender A la mayoría de los científicos no se les paga como programadores, ni tampoco se les ha capacitado para ello. Necesitan poder dibujar una curva, suavizar una señal, hacer una transformada de Fourier en unos minutos.\nComunicación sencilla Para mantener vivo el código dentro de un laboratorio o una empresa, los colaboradores, estudiantes o tal vez los clientes deben poder leerlo como un libro. La sintaxis de Python es simple, evitando símbolos extraños o especificaciones de rutina largas que desviarían al lector de la comprensión matemática o científica del código.\nLos módulos numéricos de código eficiente de Python son computacionalmente eficientes. Pero no hace falta decir que un código muy rápido se vuelve inútil si se dedica demasiado tiempo a escribirlo. Python apunta a tiempos de desarrollo rápidos y tiempos de ejecución rápidos.\nUniversal Python es un lenguaje que se usa para muchos problemas diferentes. Aprender Python evita aprender un nuevo software para cada nuevo problema.'
for oracion in texto_español.text.split('\n'):
print('-.-')
print(oracion)
-.-
Pilas incluidas Amplia colección de ladrillos ya existentes de métodos numéricos clásicos, herramientas de trazado o procesamiento de datos. No queremos reprogramar el trazado de una curva, una transformada de Fourier o un algoritmo de ajuste. ¡No reinventes la rueda!
-.-
Fácil de aprender A la mayoría de los científicos no se les paga como programadores, ni tampoco se les ha capacitado para ello. Necesitan poder dibujar una curva, suavizar una señal, hacer una transformada de Fourier en unos minutos.
-.-
Comunicación sencilla Para mantener vivo el código dentro de un laboratorio o una empresa, los colaboradores, estudiantes o tal vez los clientes deben poder leerlo como un libro. La sintaxis de Python es simple, evitando símbolos extraños o especificaciones de rutina largas que desviarían al lector de la comprensión matemática o científica del código.
-.-
Los módulos numéricos de código eficiente de Python son computacionalmente eficientes. Pero no hace falta decir que un código muy rápido se vuelve inútil si se dedica demasiado tiempo a escribirlo. Python apunta a tiempos de desarrollo rápidos y tiempos de ejecución rápidos.
-.-
Universal Python es un lenguaje que se usa para muchos problemas diferentes. Aprender Python evita aprender un nuevo software para cada nuevo problema.
1. Tipos de variables
# esto
nombre = 'hola'
#los comentarios sirven para ir explicando el codigo
#integer
numero = 2
#float
numero_con_coma = 2.5
# #el booleano puede ser True or False
# #boolean
booleano = True
#algunos operadores
multiplicacion = 4 * 5
potencia = 4 ** 5
divisor = 10/6
divisor_entero = 10//6
divisor
1.6666666666666667
type(1 == 1)
bool
Estructura de datos
Listas, set, tuplas y diccionario
#podemos guardar los datos en listas
lista = ['a', 'b', 1, 3]
#podemos usar otros tipos de datos como
tupla = ('a', 1)
lista_de_tuplas = [('juan', 10), ('María', 18)]
triplet = ('a', 4, 5)
etc = (1, 2, 3, 4, 5, 6)
#diccionarios
diccionario = {'k' : 34, 'f' : 35, 't':42}
diccionario
{'f': 35, 'k': 34, 't': 42}
diccionario.keys()
dict_keys(['k', 'f', 't'])
diccionario.values()
dict_values([34, 35, 42])
asd = {'f':'asdasd', 4:56.7}
asd.keys()
dict_keys(['f', 4])
lista_de_diccionarios = [{'f':5},{'g':6}]
lista_de_diccionarios[0]
{'f': 5}
Indexing
Extraer elementos de estructura de datos
lista
['a', 'b', 1, 3]
lista[0:2]
['a', 'b']
lista[-1]
3
Si quisiera guardar los datos de todos mis alumnos utilizo una lista de tuplas:
alumnos = [('juan', 35, 2), ('hernan', 32, 5), ('maría', 33, 0)]
#texto también es iterable
alumnos[0][0][1]
'u'
Slicing
lista_n = [1,2,3,4,5,6,7,8,9]
# start:stop:step
# start::step
# start:stop
# start ::
# :: end
lista_n[2:5]
[3, 4, 5]
Algunos operadores
str(12.34)
'12.34'
max([1,2,3,4,5,16,5,4,3,11])
16
Funciones
# Escribir una función que recibe la longitud del lado de un cuadrado y retorna el área del cuadrado
def areaSquare(lado):
resultado = lado ** 2
print('tu resultado es ', resultado)
return resultado
result = areaSquare(lado = 4)
tu resultado es 16
# Escribir una función que recibe el largo, ancho y profundidad de un ”cuboide” y retorna el área de la superficie del ”cuboide”
def surfaceAreaCuboid(largo,ancho,profundidad):
superficie = 2 * (largo * ancho + largo * profundidad + ancho * profundidad)
return superficie
Ahora llamamos a las funciones definidas anteriormente
areaSquare(3)
9
surfaceAreaCuboid(1,3,5)
46
Numpy & Scipy
Funciones para hacer y trabajar audio. Ambientes científicos.
An introduction to Numpy and Scipy
import numpy as np
from scipy import signal
import random
array = np.array([[1,2,3,4,5],[1,2,3,4,4]])
array.max()
5
array.T
array([[1, 1],
[2, 2],
[3, 3],
[4, 4],
[5, 4]])
x = np.array([1., -1., -2., 3])
x[1]
-1.0
x > 1
array([False, False, False, True])
x[x > 0]
array([1., 3.])
np.cos(x)
array([ 0.54030231, 0.54030231, -0.41614684, -0.9899925 ])
El sonido.
- El sonido en la física.
- El sonido en una computadora.
- Cómo se traduce una función continua e infinitamente densa.
$y=A * sin({2\pi f t})$
- f = frecuencia
- t = tiempo
$w = 2\pif$
- A = 1
$y=sin({w*t})$
El sonido digital
Cómo interpreta una computadora el sonido?
- sampling
- cuantización

#Para reproducir audio en la Jupyter N.
from IPython.display import Audio, display
import numpy as np
#cantidad de puntos por segundo
framerate = 44100
#cinco segundos de audio
t = np.linspace(0,5,framerate*5)
f = 440
data = np.sin( 2*np.pi*f*t)
def simple_wave(f, t, framerate = 44100, A = 1):
'''función simple para armar una onda sonora
inputs:
f: frecuencia, float
t: tiempo, float
framerate: sampleo
A: amplitud, por default 1
return:
onda: numpy array
'''
t = np.linspace(0, t, int(framerate*t))
resultado = A*np.sin(2*np.pi*f*t)
return resultado
la440 = simple_wave(f=440, t=5)
Audio(data=la440, rate=44100)
Distancia entre notas occidentales: intervalos de media nota.
$y=f_{0}*2^\frac{n}{12}$
#Escala musical
n_0 = 440
#lista por comprension
notas = [440*2**(n/12) for n in range(13)]
sonidos = [simple_wave(f, 2) for f in notas]
sonidos
[array([ 0.00000000e+00, 6.26490336e-02, 1.25051934e-01, ...,
-1.25051934e-01, -6.26490336e-02, 1.25522677e-13]),
array([0. , 0.06636901, 0.13244536, ..., 0.93790486, 0.912814 ,
0.88369789]),
array([ 0. , 0.07030919, 0.14027038, ..., -0.99933694,
-0.99942377, -0.99456395]),
array([ 0. , 0.07448246, 0.14855114, ..., 0.13448671,
0.06030733, -0.01420708]),
array([ 0. , 0.07890246, 0.15731294, ..., -0.96096114,
-0.97979619, -0.9925219 ]),
array([ 0. , 0.0835836 , 0.16658224, ..., -0.73935663,
-0.79304745, -0.84118817]),
array([ 0. , 0.08854108, 0.17638667, ..., 0.12711315,
0.03879106, -0.04983572]),
array([ 0. , 0.09379095, 0.18675502, ..., 0.12328134,
0.02966242, -0.06421801]),
array([ 0. , 0.09935014, 0.19771722, ..., -0.67880378,
-0.60249065, -0.52021593]),
array([ 0. , 0.10523652, 0.20930433, ..., -0.34387084,
-0.24314252, -0.13971397]),
array([ 0. , 0.1114689 , 0.22154843, ..., -0.33170315,
-0.224478 , -0.11445491]),
array([0. , 0.11806709, 0.23448256, ..., 0.90780231, 0.95096993,
0.98083467]),
array([ 0.00000000e+00, 1.25051934e-01, 2.48140602e-01, ...,
-2.48140602e-01, -1.25051934e-01, 2.51045353e-13])]
Audio(sonidos[0], rate=44100)
Audio(sonidos[1], rate=44100)
#1, 3, 4, 5 y 7
#encontrar notas de la escala pentatónica mayor de La
#la, La#, si, do, do#, re, re#, mi, fa, fa#, sol, sol#, la
len(sonidos)
13
posiciones = [0,4,5,7,11,12]
#indexado más lista por comprensión
escala_pentatonica = [sonidos[i] for i in posiciones]
#juntamos las notas de la pentatónica
audio_concatenado = np.concatenate(escala_pentatonica)
Audio(audio_concatenado, rate=44100)
# solo de computadora
# negra 1 segundo
tiempos = [1, 2, 0.5, 0.25, 0.25]*4
pentatonic_freqs = [notas[i] for i in posiciones]*4
random.shuffle(pentatonic_freqs)
random.shuffle(tiempos)
solo = np.concatenate([simple_wave(f,t,44100) for f,t in zip(pentatonic_freqs, tiempos)])
Audio(solo, rate =44100)
#sum([simple_wave(f,4) for f in []])
acorde_do = simple_wave(261.63, 4, 44100) + simple_wave(349.228, 4, 44100) + simple_wave(392, 4, 44100)
acorde_fa = simple_wave(349.228, 2, 44100) + simple_wave(440, 2, 44100) + simple_wave(261.63*2, 2, 44100)
acorde_sol = simple_wave(392, 2, 44100) + simple_wave(494, 2, 44100) + simple_wave(587.33, 2, 44100)
Audio(acorde_sol, rate=44100)
base = np.concatenate([np.concatenate([acorde_do, acorde_fa, acorde_sol]), np.concatenate([acorde_do, acorde_fa, acorde_sol])])
Audio(base, rate=44100)
musiquita = base + solo
Audio(musiquita, rate=44100)
Gráficos: Librería Matplotlib
#Para plotear
import matplotlib.pyplot as plt
plt.style.use('seaborn-darkgrid')
%matplotlib inline
plt.figure(figsize=(5,5))
la440 = simple_wave(440, 5, 44100)
t = np.linspace(0, 5, 44100*5)
plt.xlim(0, 0.005)
plt.plot(t, la440)
plt.grid()
plt.xlabel('tiempo')
plt.ylabel('amplitud')
plt.show()
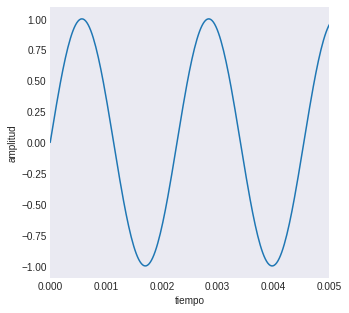
Operaciones entre señales
Más alla de las funciones trigonométricas. Operaciones entre señales.
#señal triangular
t = np.linspace(0, 1, 44100)
#2*pi*f*t
plt.xlim([0, 0.005])
triangle = signal.sawtooth(2 * np.pi * 800 * t, 0.5)
plt.plot(t, triangle)
[<matplotlib.lines.Line2D at 0x7f18c872b7f0>]
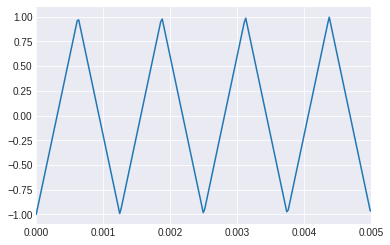
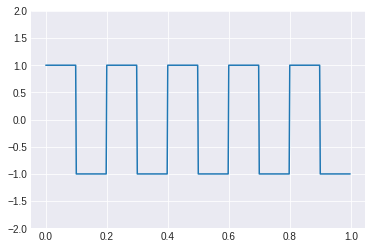
t = np.linspace(0, 1, 500, endpoint=False)
square = signal.square(2 * np.pi * 5 * t)
plt.plot(t, square)
plt.ylim(-2, 2)
(-2.0, 2.0)
t = np.linspace(0, 5, 44100*5)
w = signal.chirp(t, f0=1, f1=1500, t1=5, method='quadratic' )
plt.plot(t, w)
plt.xlim([0, 2])
plt.xlabel('t (sec)')
plt.show()
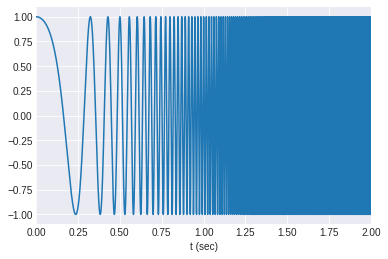
Audio(w, rate=44100)
#Armar una señal compleja con una función seno.
def simple_cos_wave(f, t, framerate, A = 1):
'''Funcion para crear una onda cos
inputs:
f = frecuencia, int
t = tiempo, int
A = amplitud, int
return:
wave = onda senoidal, np.array
'''
t = np.linspace(0, t, framerate*t)
return A*np.cos(2*np.pi*f*t)
cos_1 = simple_cos_wave(300, 5, 44100)
cos_2 = simple_cos_wave(400, 5, 44100)
sin_1 = simple_wave(500, 5, 44100)
sin_2 = simple_wave(200, 5, 44100)
suma_de_señales = cos_1 + cos_2 + sin_1 + sin_2
plt.figure()
t = np.linspace(0, 5, 44100*5)
plt.plot(t, suma_de_señales)
plt.xlim([0, 0.05])
plt.grid()
plt.show()
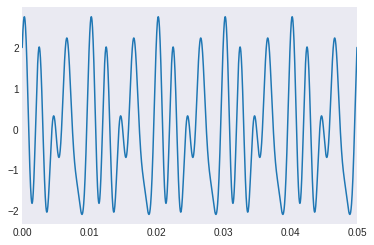
Audio(suma_de_señales, rate=44100)
Generando ruido
#distribución gauseana
mean = 0
std = 1
framerate = 44100
seconds = 5
num_samples = seconds*framerate
noise = np.random.normal(mean, std, size=num_samples)
x = np.linspace(0, seconds, num_samples)
plt.plot(x, noise)
plt.show()
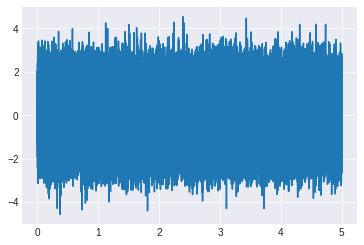
Audio(0.5*noise, rate=framerate)
sin_noise = sin_1 + noise
Audio(sin_noise, rate = framerate)
Dominio de frecuencias
Fourier. análisis frecuenciar
from scipy.fft import fft, fftshift
def fourier_calculation(y, framerate):
'''Aplicando fast fourier transform'''
yf = fft(y)
N = len(y)
yf = 2.0/N *np.abs(yf[0:N//2])
xf = np.linspace(0.0, 1/2*framerate, N//2)
return yf, xf
yf, xf = fourier_calculation(w, framerate = 44100)
plt.xlim([0, 1000])
plt.plot(xf, yf)
[<matplotlib.lines.Line2D at 0x7f18c7ff2ba8>]
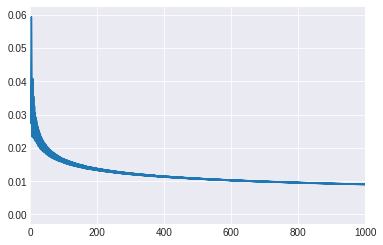
yf, xf = fourier_calculation(suma_de_señales, framerate = 44100)
plt.plot(xf, yf)
plt.xlim([0, 1000])
(0.0, 1000.0)
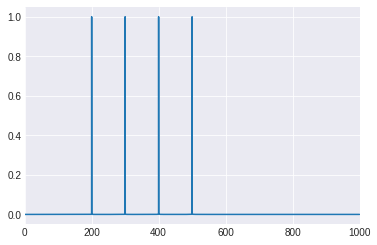
Espectograma
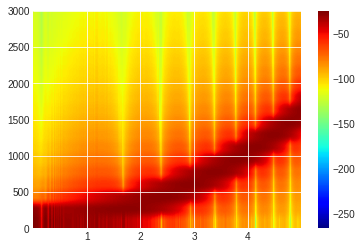
a = plt.specgram(w, Fs=44100, cmap='jet')
plt.ylim([0,3000])
plt.colorbar()
plt.show()
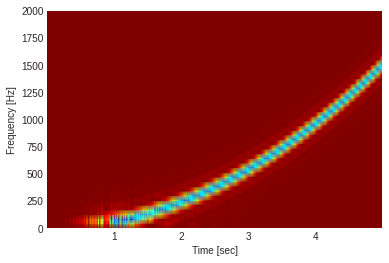
f, t, Sxx = signal.spectrogram(w, fs=44100, nperseg=256*2, nfft=512*2)
plt.pcolormesh(t, f, Sxx, shading='gouraud', cmap='jet_r')
plt.ylim([0,2000])
plt.ylabel('Frequency [Hz]')
plt.xlabel('Time [sec]')
plt.show()
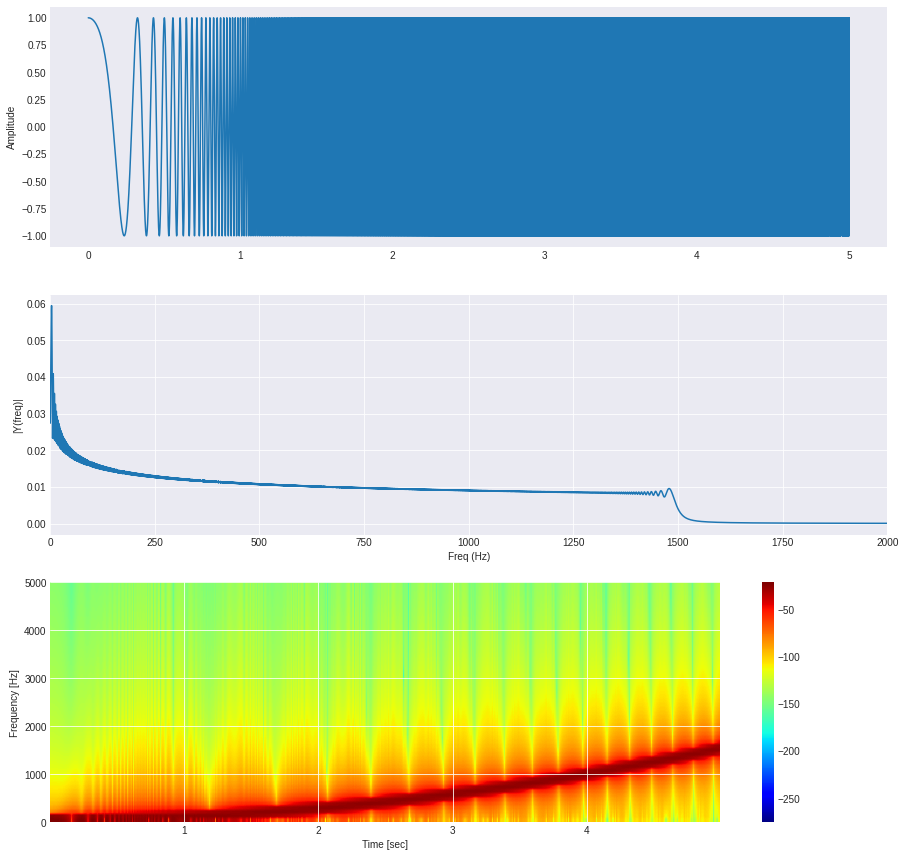
def plot_multiple(y, fs = 44100, plot_type = 'plotly'):
'''Plotea primero la onda en dominio de tiempo, luego el espectro (FFT) y luego el espectrograma'''
#Creo el espacio para plotear, una "figura" vacia
plt.figure(figsize=(15,15))
x = np.linspace(0, len(y)/fs, len(y))
#Dividido en 3 filas y 1 columna, ploteo la onda en el 1er espacio
plt.subplot(3, 1, 1)
#plt.xlim([0, 0.005])
plt.plot(x, y)
#Pongo titulo al eje y
plt.ylabel('Amplitude')
#Grilla de fondo
plt.grid()
#FFT
#n = len(w) = duración * framerate
yf, xf = fourier_calculation(y, fs)
#Plot FFT
plt.subplot(3, 1, 2)
#Ploteo las frecuencias positivas y sus valores, con un color RGBA
plt.xlabel('Freq (Hz)')
plt.ylabel('|Y(freq)|')
plt.xlim([0,2000])
plt.plot(xf, yf)
#plot spectogram
if plot_type == 'scipy':
plt.subplot(3, 1, 3)
f, t, Sxx = signal.spectrogram(y, fs, scaling='density')
plt.pcolormesh(t, f, Sxx, shading='gouraud', cmap='jet_r')
plt.specgram(y, Fs =fs)
plt.ylabel('Frequency [Hz]')
plt.xlabel('Time [sec]')
plt.ylim([0,2000])
plt.show()
else:
plt.subplot(3, 1, 3)
a = plt.specgram(y, Fs=fs, NFFT=256*2, cmap='jet')
plt.ylim([0,5000])
plt.ylabel('Frequency [Hz]')
plt.xlabel('Time [sec]')
plt.colorbar()
plt.show()
plot_multiple(w)
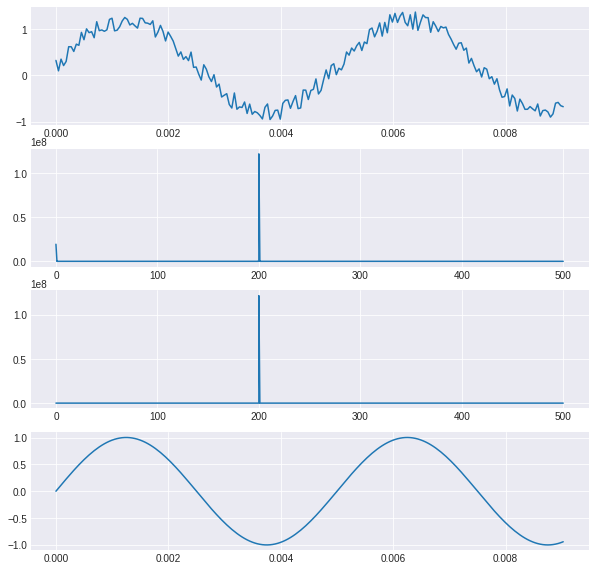
Filtrado
Filtrado a través de Fourier
import numpy as np
import scipy.fftpack
plt.subplots(4, 1, figsize=(10, 10))
N = 22050
secs = 1
f = 200
x = np.linspace(0,secs, N*secs)
# sumamos señal mas ruido
y = np.sin(2*np.pi*f*x) + np.random.random(N*secs) * 0.4
plt.subplot(4,1,1)
plt.plot(x[0:200],y[0:200])
#pasamos a dominio de frecuencias
w = scipy.fftpack.rfft(y)
f = scipy.fftpack.rfftfreq(N*secs, x[1]-x[0])
spectrum = w**2
plt.subplot(4,1,2)
plt.plot(f[0:1000], spectrum[0:1000])
# sacamos frecuencias bajas con indexing booleano
cutoff_idx = spectrum < (spectrum.max()/5)
w2 = w.copy()
w2[cutoff_idx] = 0
spectrum2 = w2**2
plt.subplot(4,1,3)
plt.plot(f[0:1000], spectrum2[0:1000])
#inversa de furier
y2 = scipy.fftpack.irfft(w2)
plt.subplot(4,1,4)
plt.plot(x[0:200], y2[0:200])
[<matplotlib.lines.Line2D at 0x7f18c8118e48>]
Practicando con grabaciones reales
from scipy.io import wavfile
import scipy.io
"""
To write this piece of code I took inspiration/code from a lot of places.
It was late night, so I'm not sure how much I created or just copied o.O
Here are some of the possible references:
https://blog.addpipe.com/recording-audio-in-the-browser-using-pure-html5-and-minimal-javascript/
https://stackoverflow.com/a/18650249
https://hacks.mozilla.org/2014/06/easy-audio-capture-with-the-mediarecorder-api/
https://air.ghost.io/recording-to-an-audio-file-using-html5-and-js/
https://stackoverflow.com/a/49019356
"""
from IPython.display import HTML, Audio
from google.colab.output import eval_js
from base64 import b64decode
import numpy as np
from scipy.io.wavfile import read as wav_read
import io
import ffmpeg
AUDIO_HTML = """
<script>
var my_div = document.createElement("DIV");
var my_p = document.createElement("P");
var my_btn = document.createElement("BUTTON");
var t = document.createTextNode("Press to start recording");
my_btn.appendChild(t);
//my_p.appendChild(my_btn);
my_div.appendChild(my_btn);
document.body.appendChild(my_div);
var base64data = 0;
var reader;
var recorder, gumStream;
var recordButton = my_btn;
var handleSuccess = function(stream) {
gumStream = stream;
var options = {
//bitsPerSecond: 8000, //chrome seems to ignore, always 48k
mimeType : 'audio/webm;codecs=opus'
//mimeType : 'audio/webm;codecs=pcm'
};
//recorder = new MediaRecorder(stream, options);
recorder = new MediaRecorder(stream);
recorder.ondataavailable = function(e) {
var url = URL.createObjectURL(e.data);
var preview = document.createElement('audio');
preview.controls = true;
preview.src = url;
document.body.appendChild(preview);
reader = new FileReader();
reader.readAsDataURL(e.data);
reader.onloadend = function() {
base64data = reader.result;
//console.log("Inside FileReader:" + base64data);
}
};
recorder.start();
};
recordButton.innerText = "Recording... press to stop";
navigator.mediaDevices.getUserMedia({audio: true}).then(handleSuccess);
function toggleRecording() {
if (recorder && recorder.state == "recording") {
recorder.stop();
gumStream.getAudioTracks()[0].stop();
recordButton.innerText = "Saving the recording... pls wait!"
}
}
// https://stackoverflow.com/a/951057
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
var data = new Promise(resolve=>{
//recordButton.addEventListener("click", toggleRecording);
recordButton.onclick = ()=>{
toggleRecording()
sleep(2000).then(() => {
// wait 2000ms for the data to be available...
// ideally this should use something like await...
//console.log("Inside data:" + base64data)
resolve(base64data.toString())
});
}
});
</script>
"""
def get_audio():
display(HTML(AUDIO_HTML))
data = eval_js("data")
binary = b64decode(data.split(',')[1])
process = (ffmpeg
.input('pipe:0')
.output('pipe:1', format='wav')
.run_async(pipe_stdin=True, pipe_stdout=True, pipe_stderr=True, quiet=True, overwrite_output=True)
)
output, err = process.communicate(input=binary)
riff_chunk_size = len(output) - 8
# Break up the chunk size into four bytes, held in b.
q = riff_chunk_size
b = []
for i in range(4):
q, r = divmod(q, 256)
b.append(r)
# Replace bytes 4:8 in proc.stdout with the actual size of the RIFF chunk.
riff = output[:4] + bytes(b) + output[8:]
sr, audio = wav_read(io.BytesIO(riff))
return audio, sr
grabacion, sr = get_audio()
print(f"number of channels = {len(grabacion.shape)}")
length = grabacion.shape[0] / sr
print(f"length = {length}s")
number of channels = 1
length = 11.58s
plot_multiple(grabacion, sr)
/usr/local/lib/python3.6/dist-packages/matplotlib/axes/_axes.py:7592: RuntimeWarning: divide by zero encountered in log10
Z = 10. * np.log10(spec)
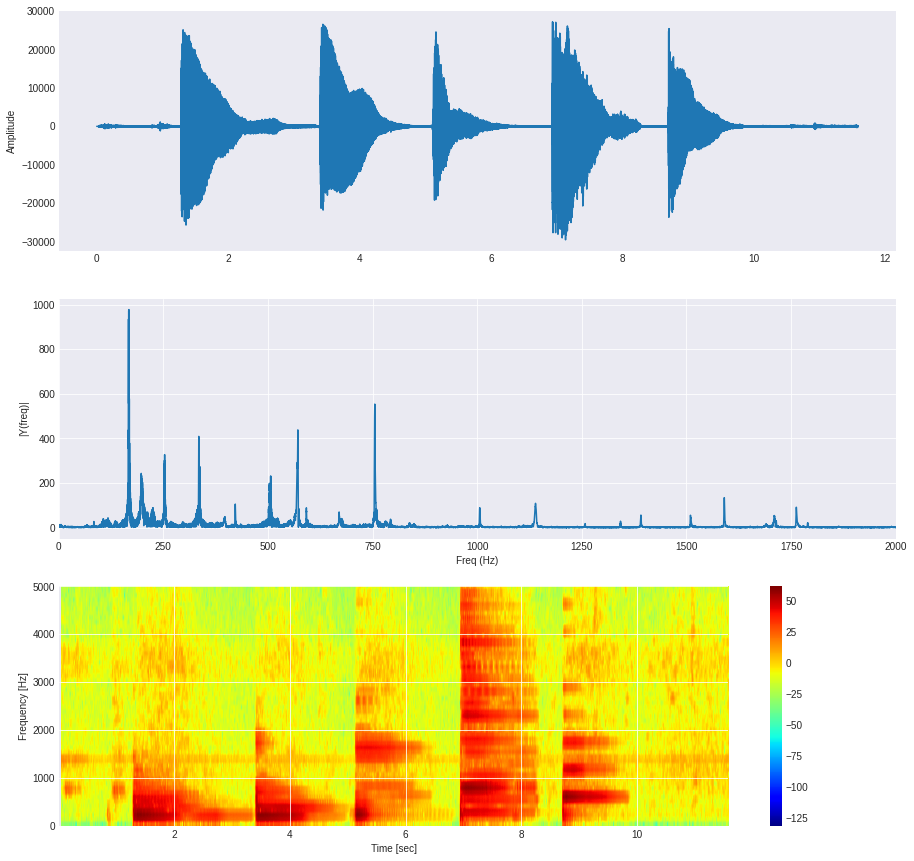
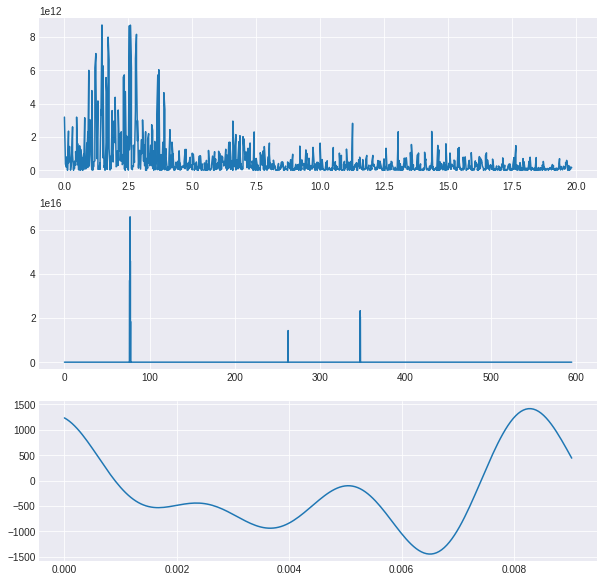
plt.subplots(3, 1, figsize=(10, 10))
w = scipy.fftpack.rfft(grabacion)
f = scipy.fftpack.rfftfreq(len(grabacion), x[1]-x[0])
spectrum = w**2
plt.subplot(3,1,1)
plt.plot(f[0:1000], spectrum[0:1000])
cutoff_idx = spectrum < (spectrum.max()/5)
w2 = w.copy()
w2[cutoff_idx] = 0
spectrum2 = w2**2
plt.subplot(3,1,2)
plt.plot(f[0:30000], spectrum2[0:30000])
y2 = scipy.fftpack.irfft(w2)
plt.subplot(3,1,3)
plt.plot(x[0:200], y2[0:200])
[<matplotlib.lines.Line2D at 0x7f18c71cae48>]
Audio(y2, rate = sr)
Posibles aplicaciones
deepspeech
- Install DeepSpeech
You can install DeepSpeech with pip (make it deepspeech-gpu==0.6.0 if you are using GPU in colab runtime).
- Download and unzip models
!wget https://github.com/mozilla/DeepSpeech/releases/download/v0.9.1/deepspeech-0.9.1-models.pbmm
!wget https://github.com/mozilla/DeepSpeech/releases/download/v0.9.1/deepspeech-0.9.1-models.scorer
--2020-11-11 16:44:17-- https://github.com/mozilla/DeepSpeech/releases/download/v0.9.1/deepspeech-0.9.1-models.pbmm
Resolving github.com (github.com)... 52.192.72.89
Connecting to github.com (github.com)|52.192.72.89|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://github-production-release-asset-2e65be.s3.amazonaws.com/60273704/43c19b00-1ea9-11eb-9e8a-349c106bb0f3?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20201111%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201111T164417Z&X-Amz-Expires=300&X-Amz-Signature=9896623178cf74df82c3d476dfa3d1ecc4efb2e51c04fb057cc75abdb21e9f2b&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=60273704&response-content-disposition=attachment%3B%20filename%3Ddeepspeech-0.9.1-models.pbmm&response-content-type=application%2Foctet-stream [following]
--2020-11-11 16:44:17-- https://github-production-release-asset-2e65be.s3.amazonaws.com/60273704/43c19b00-1ea9-11eb-9e8a-349c106bb0f3?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20201111%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201111T164417Z&X-Amz-Expires=300&X-Amz-Signature=9896623178cf74df82c3d476dfa3d1ecc4efb2e51c04fb057cc75abdb21e9f2b&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=60273704&response-content-disposition=attachment%3B%20filename%3Ddeepspeech-0.9.1-models.pbmm&response-content-type=application%2Foctet-stream
Resolving github-production-release-asset-2e65be.s3.amazonaws.com (github-production-release-asset-2e65be.s3.amazonaws.com)... 52.216.145.99
Connecting to github-production-release-asset-2e65be.s3.amazonaws.com (github-production-release-asset-2e65be.s3.amazonaws.com)|52.216.145.99|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 188915987 (180M) [application/octet-stream]
Saving to: ‘deepspeech-0.9.1-models.pbmm.1’
deepspeech-0.9.1-mo 100%[===================>] 180.16M 16.5MB/s in 12s
2020-11-11 16:44:30 (14.9 MB/s) - ‘deepspeech-0.9.1-models.pbmm.1’ saved [188915987/188915987]
--2020-11-11 16:44:30-- https://github.com/mozilla/DeepSpeech/releases/download/v0.9.1/deepspeech-0.9.1-models.scorer
Resolving github.com (github.com)... 52.192.72.89
Connecting to github.com (github.com)|52.192.72.89|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://github-production-release-asset-2e65be.s3.amazonaws.com/60273704/eda12780-1ea9-11eb-9846-1bea4a4e4347?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20201111%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201111T164430Z&X-Amz-Expires=300&X-Amz-Signature=45d480a2dc7d1fb116dce759cb870085b95885263138098bd9eb370f4868bbef&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=60273704&response-content-disposition=attachment%3B%20filename%3Ddeepspeech-0.9.1-models.scorer&response-content-type=application%2Foctet-stream [following]
--2020-11-11 16:44:30-- https://github-production-release-asset-2e65be.s3.amazonaws.com/60273704/eda12780-1ea9-11eb-9846-1bea4a4e4347?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20201111%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201111T164430Z&X-Amz-Expires=300&X-Amz-Signature=45d480a2dc7d1fb116dce759cb870085b95885263138098bd9eb370f4868bbef&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=60273704&response-content-disposition=attachment%3B%20filename%3Ddeepspeech-0.9.1-models.scorer&response-content-type=application%2Foctet-stream
Resolving github-production-release-asset-2e65be.s3.amazonaws.com (github-production-release-asset-2e65be.s3.amazonaws.com)... 52.217.39.116
Connecting to github-production-release-asset-2e65be.s3.amazonaws.com (github-production-release-asset-2e65be.s3.amazonaws.com)|52.217.39.116|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 953363776 (909M) [application/octet-stream]
Saving to: ‘deepspeech-0.9.1-models.scorer.1’
deepspeech-0.9.1-mo 100%[===================>] 909.20M 16.5MB/s in 57s
2020-11-11 16:45:29 (15.9 MB/s) - ‘deepspeech-0.9.1-models.scorer.1’ saved [953363776/953363776]
import deepspeech
from scipy.io import wavfile
import scipy.io
import numpy as np
import librosa
model_file_path = 'deepspeech-0.9.1-models.pbmm'
model = deepspeech.Model(model_file_path)
0
model.sampleRate()
16000
speech, sr = get_audio()
speech = speech.astype(float)
librosa.output.write_wav('speech.wav', speech, sr)
y, s = librosa.load('speech.wav', sr=16000)
Audio(y,rate = s)
data16 = np.frombuffer(y, dtype=np.int16)
model.stt(data16)
Otras aplicaciones interesantes